Tinker Flywheel
A research memo for Thinking Machines Lab — 2,000+ public developer signals on fine-tuning pain, surfacing the gap between a training tool and a training platform.
The problem
Thinking Machines Lab shipped Tinker as a fine-tuning API. I wanted to understand what happens after a developer runs it — what stops them from coming back for a second run, a third, a tenth. If Tinker wants to be a platform and not a one-off tool, the answer matters.
My hypothesis
Public developer conversation is a better signal for this than interviews. If I pulled 18 months of signal across Reddit, Hacker News, GitHub, Stack Overflow, and similar sources — then mapped the friction to phases of the fine-tuning lifecycle — the pattern would tell me where Tinker's roadmap gap is.
What I built
A research memo at schlacter.me/tinker-flywheel backed by a live data pipeline: 2,000+ deduplicated public signals tagged to themes and three lifecycle phases (Train → Evaluate → Iterate). The memo opens with the headline — most post-fine-tuning pain is evaluation: did it get better, is the data clean, did anything break. Iteration questions barely register because developers can't see past the first checkpoint. An interactive theme drill lets readers click into each theme and see the raw source posts.
What broke
Reddit skews toward people who wanted to say something, usually strongly. This is a signal-finding exercise, not a population estimate. The memo says so explicitly — but the caveat is easy to miss, and a PM reading quickly could over-index on loudness. The bigger limitation: I don't have access to Tinker's actual support logs, so this is a public mirror of what the real signal probably looks like.
What I learned
Every theme in the data ladders back to one question. A fine-tuning API that also answers 'did it get better?' closes the loop developers can't close today — and loops compound. Writing the memo forced a sharp product claim I didn't have going in: the gap between a training tool and a training platform is evaluation.
If I kept going
If I kept going: wire the pipeline to refresh weekly so the memo updates as the conversation evolves. Add a second corpus (Tinker's Discord, HF Forum threads on their org page) to triangulate with platform-specific signal. And write a shorter companion memo on the 23% — the iteration themes developers feel but haven't named yet.
Prototype
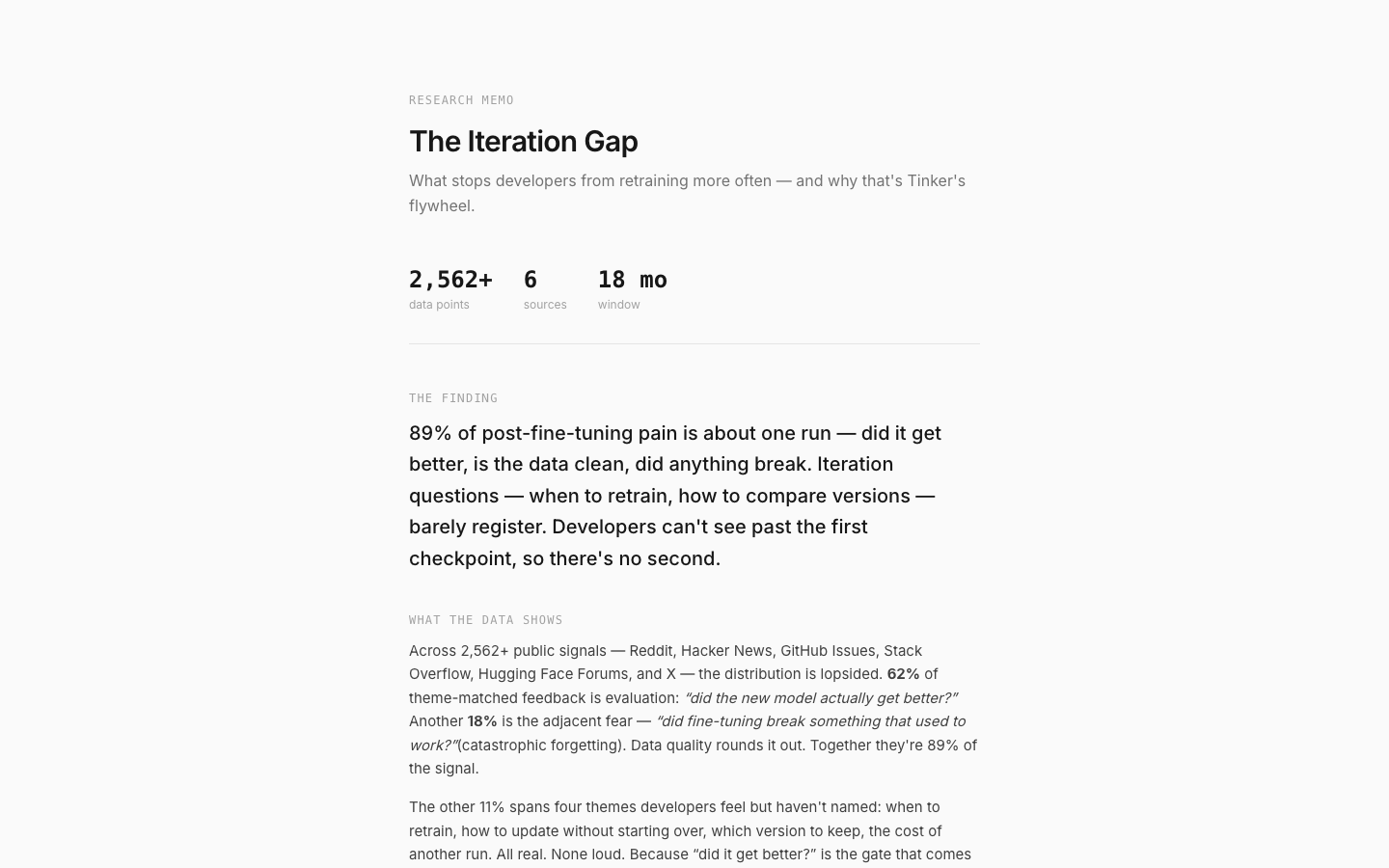
The finding: 77% of post-fine-tuning pain is about one run — evaluation, data quality, catastrophic forgetting.
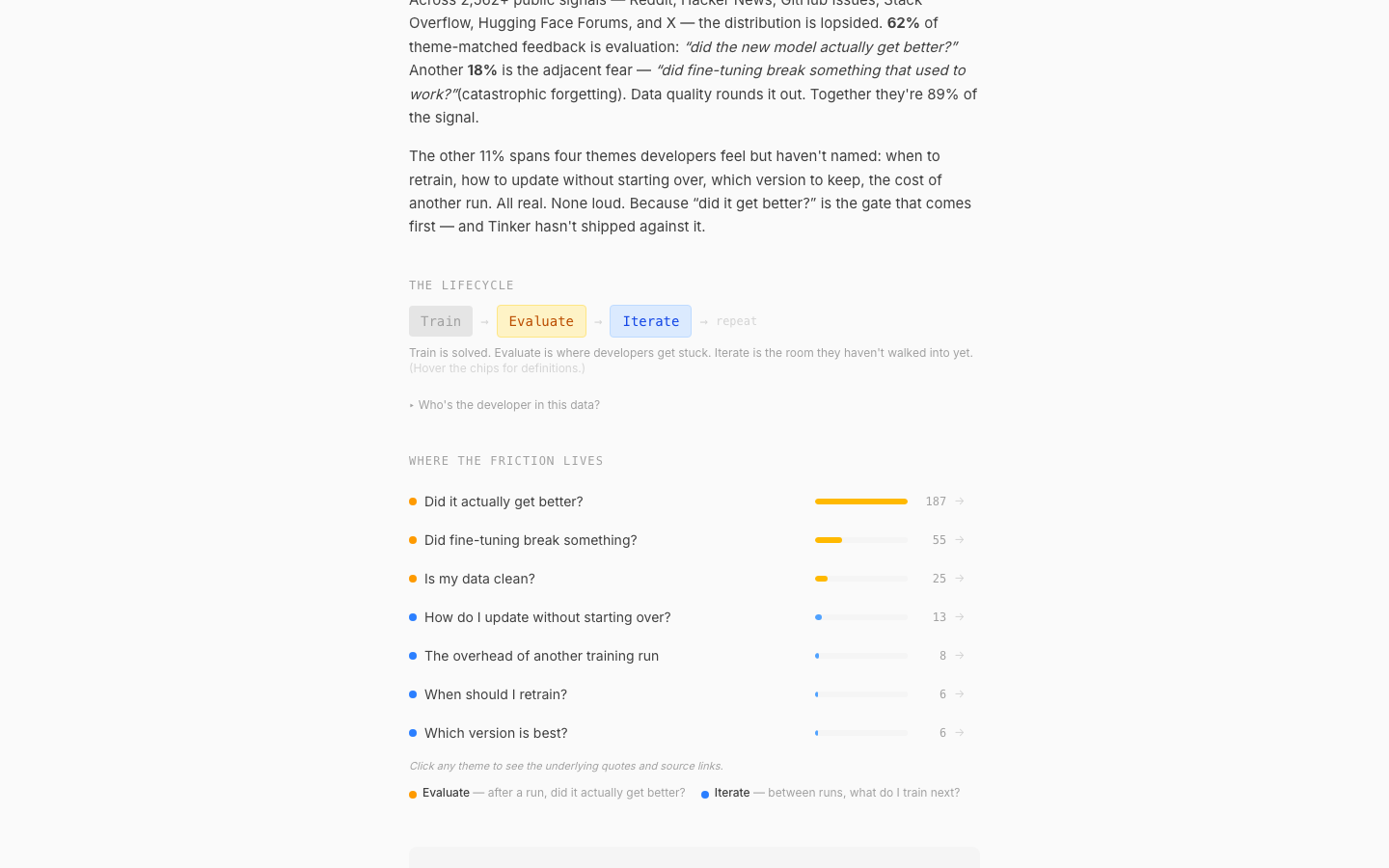
Theme drill: click any theme to see the raw source posts backing the claim.
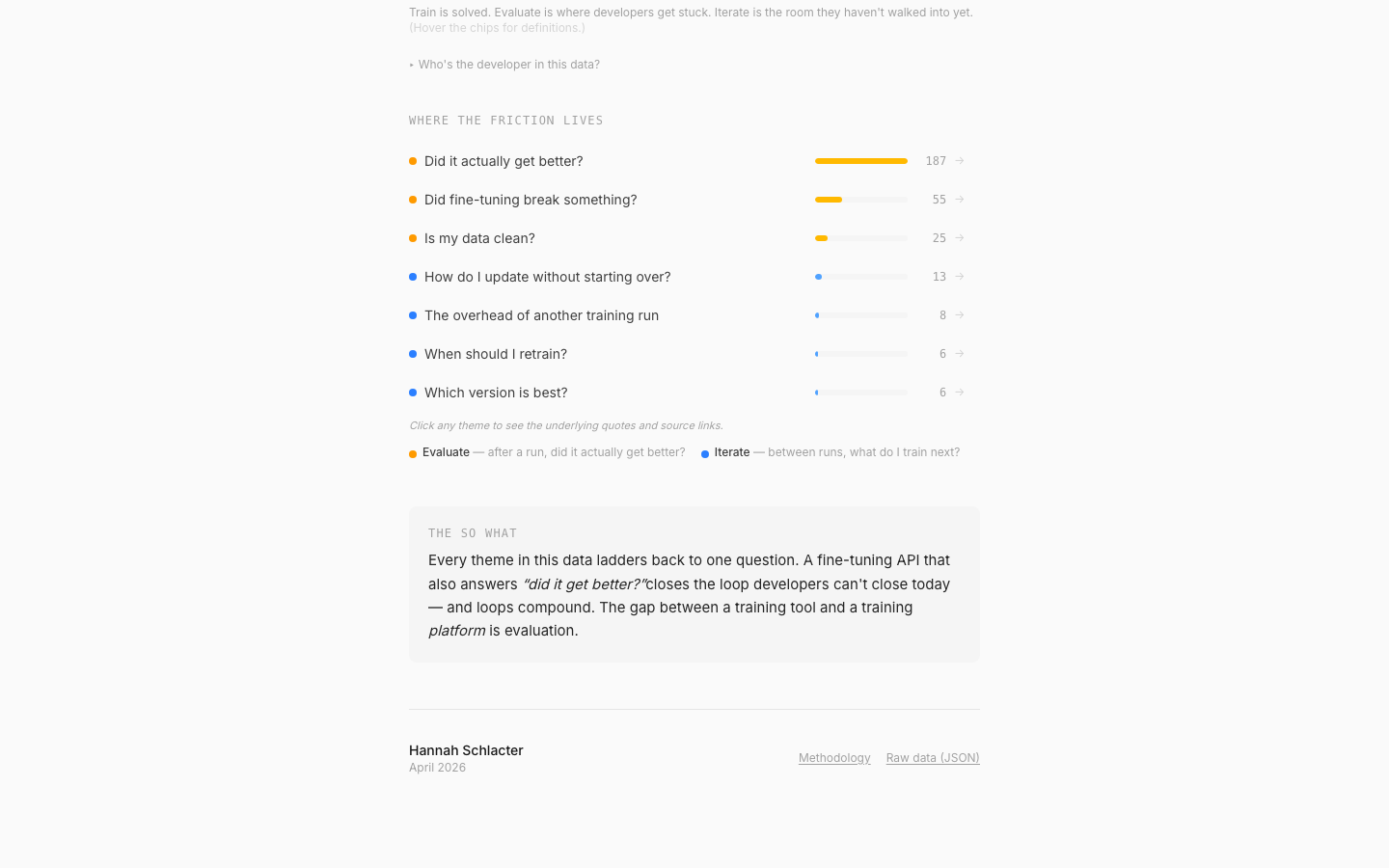
The so-what: the gap between a training tool and a training platform is evaluation.